
Split-Testing is one of the really sciency parts of data science. It is one of the few methods to identify causality and create knowledge (see this post). On the other hand there are numerous ways to mess up your test design, the test implementation and the test evaluation (see this post).
Sometimes the pressure is quite high to produce test results with a significant positive improvement. Especially in a consulting-client setting consultants might be under a lot of pressure to show significant results.
I've experienced many situations where organizations start to doubt the effectiveness of ab-testing because there weren't any significant test-results. Instead of questioning the tested actions, product-changes or even capabilities of product-owners it is easier to "shoot the messenger", stop ab-testing and release features that don't affect the bottom-line.
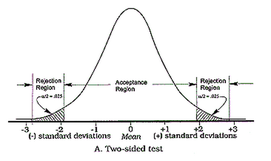
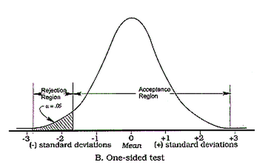
One really common trick for p-hacking and for making ab-test results "look" significant is to decide after the test-start to evaluate them on a "one-sided" basis. This leads to the p-value being only half of what it would have been in a "two-sided" evaluation. Eventually it deceives the researcher by indicating seemingly significant results more often.
Without going too much into the details, evaluating a test only on a one-sided basis changes the original alternative-hypothesis. For example from "the new feature will lead to a change in the number of sales" to "the new feature will lead to an increase in the number of sales". The only justification for using the one-sided version, i.e. only checking for increases, would be, that decreases in sales aren't of any interest (see this paper for more information on this). This in my experience is almost never the case.
So be aware if someone tells you that the test results are significant when evaluated "one-sidedly". But you should run away if someone evaluates the test "one-sided", doesn't tell you so and only announces that the test resulted in significant improvements.
Visual Website Optimizer, a provider of a web analytics and testing tool, has this split-testing significance calculator on their site: https://vwo.com/ab-split-test-significance-calculator/
Guess what method they use? Right, one-sided. Take the following example: 1000 users in your control group and 1000 in your test group. In the control group there are 21 conversion and 34 conversions in the test group. The tool would tell you that this is a significant result since the p-value is smaller than 0.05 (p-value=0.038). But evaluating this test correctly on a two-sided basis would result in a p-value of 0.076, which is not a significant result.
Visual Website Optimizer could argue having chosen a lower confidence-level than the standard 95% to increase the test's power. The greater risk of falsely accepting the alternative hypothesis might be to not notice when an action is actually successful (see type II error and statistical power). But not explicitly stating this decision raises some questions.
A much better, albeit more complex significance- and sample-size calculator is the following: http://www.evanmiller.org/ab-testing/sample-size.html. This also demonstrates the interdependence between type I- and type II-error, sample-size and effect-size.
Write a comment
Alline Talkington (Wednesday, 01 February 2017 09:10)
I read this post fully regarding the resemblance of most recent and preceding technologies, it's awesome article.
Renita Zenz (Saturday, 04 February 2017 21:13)
Hey just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Firefox. I'm not sure if this is a formatting issue or something to do with web browser compatibility but I figured I'd post to let you know. The design look great though! Hope you get the issue fixed soon. Cheers