
As already mentioned in the last post, accurately measuring all user journeys is a challenge. The tracking solution needs to integrate all channel-clicks (and preferably -views), the ones from cookies that have converted at some point and the ones from cookies that haven’t. Such a system needs to include setting cookies and referrer analysis and combines purchase-data with channel-click data on a cookie-id, i.e user-id basis. It’s decisive for the quality of the attribution modeling to spend sufficient time validating the tracking implementation. Is every campaign and channel interaction being tracked? Are there interactions that are double counted? Comparing the aggregated numbers with stats from Google Analytics or other web analytics tools is useful. But from painful experience I can only recommend to manually test as much as possible. This would include creating fake user journeys, for example by clicking on one's own google ads and test-purchasing a product. Then one should validate whether these actions have been tracked correctly as per timestamp.
For developing an attribution model the conversion event is our binary target variable (customer bought or signed up). The variables about the channel interaction (e.g. number of clicks on “paid search”) are the covariates that predict the value of the target variable.
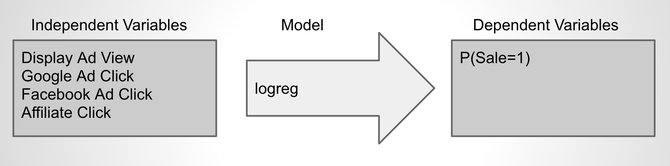
This way the modeling problem becomes a regular classification problem. These types of problems are very common to statistical modeling and machine learning, which allows us to apply proven processes and methods from these fields. These include using training- and test-sets, cross-validation and a set of metrics for measuring model quality. Common metrics for evaluating the quality of predictive models with a binary target variable are AUC (area under the curve) or a pseudo-R-squared.
Since we aim at interpreting the model's coefficient estimates as the effect of each channel interaction, we need to make sure that we have relatively robust estimators. This requires variable selection and eliminating multicollinearity, e.g. through measuring variance inflation factors.
Some seem to achieve good results with bagged logistic regression with regards to having robust estimators (see this paper). Generally speaking different modeling technique can be used such as SVMs, random forests or artificial neural nets.
Once we have sufficiently good and robust model in place, we can go ahead and “score” through every customer journey:
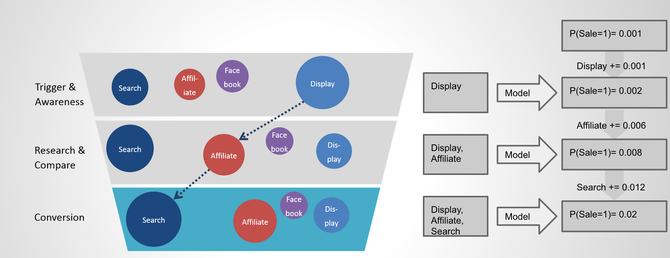
This customer journey started of with a display ad click, followed by click on an affiliate-site. The last-click right before the conversion was a paid search click. For every stage we apply the model and calculate the probability that the customer converts. We assign the incremental change of conversion probability to the latest channel. So in the "Research & Compare" phase of this particular journey the affiliate channel generated an increase in conversion probability of 0.6%, so affiliate will be assigned 0.6% of this conversion. This approach takes into account the previous channel interactions. It dynamically calculates channel effects individually per user journey instead using the same channel weights over all user journeys.
In this particular case the overall probability for a conversion-event "caused" by the user journey seems rather low (2%). If it's necessary, the whole conversion or revenue value could be distributed proportionally to the incremental probability increases, so affiliate would receive 33.33% due to this customer journey.
As a result of this process we have the number of conversions and sums of revenues attributed to each channel. These figures are than being related to calculate CPOs and ROMI which
guide re-allocation of channel budgets. In the next post I'll discuss how these steps could be integrated into one marketing attribution system and reporting tool. I will also go into
testing optimized budget allocations and taking into account device switches and cookie deletions.
Write a comment
Marco (Tuesday, 13 January 2015 23:41)
I think that after stating that "we aim at interpreting the model's coefficient estimates as the effect of each channel interaction", you should probably mention how the different models you suggest fit into this agenda. While random forest and nn generally do show very good performance, they don't allow for said interpretation and are thus best used for prediction.
Otherwise really nice article/series. I especially like the linking of (free) research papers
Brian (Thursday, 25 February 2016 12:05)
I asked a question about this (use of predicitve models). As of this time there was not real response, but I do lay out what I think is a valid approach.
http://stats.stackexchange.com/questions/197348/predictive-model-for-attribution-model/198405?noredirect=1#comment376281_198405
Richard (Monday, 04 July 2016 08:53)
Interesting example.
How do you accommodate instances where introducing a channel has a detrimental effect on the conversion rate, at least as far as the data report?
This reduction technique looks similar in approach to game theory solutions. Does the logistic regression add a stronger estimate of player value than simply evaluating conversion rate by hand?
Loriann Montague (Wednesday, 01 February 2017 22:47)
Thanks on your marvelous posting! I really enjoyed reading it, you can be a great author. I will always bookmark your blog and may come back in the foreseeable future. I want to encourage you continue your great writing, have a nice afternoon!
Dewey Magby (Friday, 03 February 2017 02:44)
Hi there, after reading this amazing article i am too glad to share my know-how here with colleagues.
Ji Pasko (Friday, 03 February 2017 03:44)
Superb blog you have here but I was curious if you knew of any community forums that cover the same topics discussed in this article? I'd really like to be a part of community where I can get advice from other experienced individuals that share the same interest. If you have any recommendations, please let me know. Bless you!
Karol Engel (Saturday, 04 February 2017 07:18)
whoah this blog is magnificent i like reading your articles. Keep up the great work! You know, many persons are searching round for this info, you can aid them greatly.
Carissa Tollett (Saturday, 04 February 2017 09:03)
I'm impressed, I have to admit. Seldom do I encounter a blog that's both educative and entertaining, and without a doubt, you have hit the nail on the head. The issue is something not enough people are speaking intelligently about. I'm very happy I stumbled across this in my search for something relating to this.
Loyd Timm (Sunday, 05 February 2017 13:32)
Excellent goods from you, man. I've understand your stuff previous to and you are just extremely fantastic. I actually like what you have acquired here, really like what you are stating and the way in which you say it. You make it enjoyable and you still take care of to keep it sensible. I can't wait to read far more from you. This is really a tremendous website.
Kalyn Hammaker (Monday, 06 February 2017 09:15)
Hey there I am so excited I found your weblog, I really found you by mistake, while I was researching on Askjeeve for something else, Anyways I am here now and would just like to say thanks a lot for a incredible post and a all round exciting blog (I also love the theme/design), I don't have time to read through it all at the moment but I have saved it and also added your RSS feeds, so when I have time I will be back to read more, Please do keep up the superb job.
Carry Tubb (Monday, 06 February 2017 10:48)
Does your blog have a contact page? I'm having a tough time locating it but, I'd like to shoot you an email. I've got some creative ideas for your blog you might be interested in hearing. Either way, great website and I look forward to seeing it improve over time.
Mitsue Gagne (Wednesday, 08 February 2017 07:48)
Oh my goodness! Amazing article dude! Thank you, However I am encountering difficulties with your RSS. I don't know why I can't subscribe to it. Is there anybody having identical RSS issues? Anyone that knows the solution can you kindly respond? Thanks!!
Jenise Linsley (Thursday, 09 February 2017 03:21)
I was recommended this blog by my cousin. I am not sure whether this post is written by him as no one else know such detailed about my trouble. You're amazing! Thanks!
Audie Benham (Thursday, 09 February 2017 03:49)
Hello! Someone in my Myspace group shared this site with us so I came to take a look. I'm definitely enjoying the information. I'm bookmarking and will be tweeting this to my followers! Wonderful blog and terrific design and style.
nfl live stream (Tuesday, 03 October 2017 01:46)
Oh my goodness! Amazing article dude! Thank you, However I am encountering difficulties with your RSS. I don't know why I can't subscribe to it. Is there anybody having identical RSS issues? Anyone that knows the solution can you kindly respond? Thanks!!